The Ultimate Guide to Consistent Hashing in System Design
Learn about consistent hashing and how it improves distributed systems' scalability and fault tolerance. Discover its benefits, implementation strategies, and real-world applications.

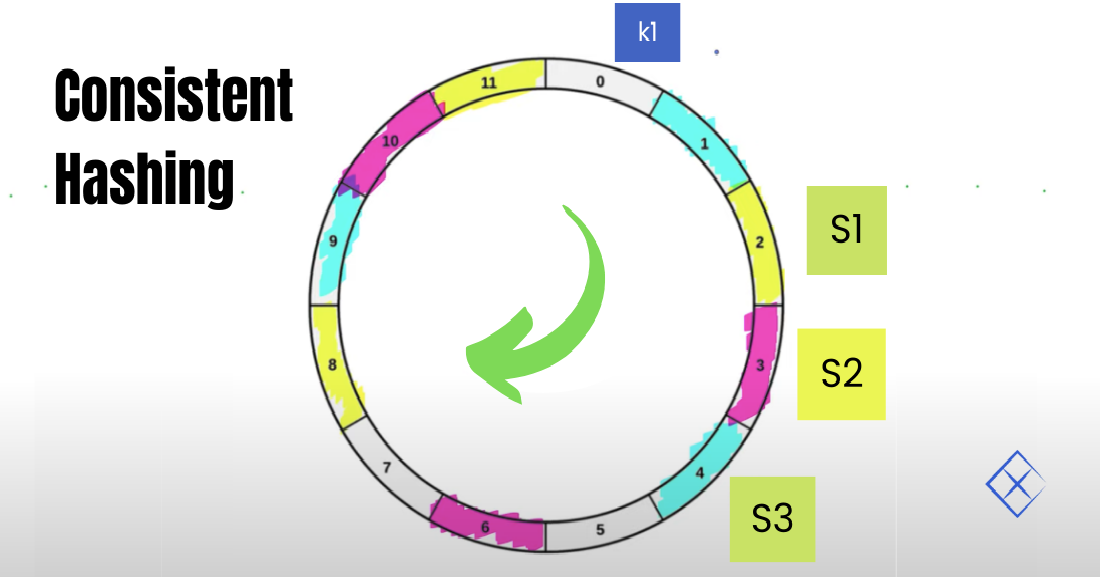
Imagine running a popular online service where thousands of users constantly access and store data. As your user base grows, you need to add more servers to handle the increasing load. But here’s the challenge: how do you efficiently distribute data across these new servers without causing major disruptions? This is where consistent hashing comes into play. It’s a clever technique used in distributed systems to manage data distribution, making sure that adding or removing servers doesn’t result in a massive data shuffle. Let’s dive into how consistent hashing works and why it’s essential for maintaining scalable and resilient systems.
What is Consistent Hashing?
Consistent hashing in system design is a method for distributing data across multiple servers to minimize disruption when servers are added or removed. It ensures that only a small portion of data needs to be reallocated, enhancing scalability and fault tolerance in distributed systems.
It is like having a magical map that helps you find and store data across a constantly changing landscape of servers. Think of it as a rotating circular table where every server and data piece has a spot. When you add a new server or remove an old one, this table shifts slightly, but most of your data stays put. This minimizes the amount of data that needs to be moved around, which is crucial for keeping your system stable and efficient.
In simpler terms, consistent hashing is a strategy used to distribute data across a cluster of servers in a way that limits the disruption caused by changes in the cluster. If you’ve ever used a cloud storage service and wondered how they handle your files so seamlessly when they add new storage nodes, consistent hashing is often part of the answer.
How Consistent Hashing Works?
Here’s how consistent hashing operates behind the scenes. Picture a giant circle where both your data and your servers are mapped using a hash function. This function assigns a unique identifier to each data item and server, placing them on this circle at various points.
When you need to store a piece of data, the hash function helps determine which server should hold it by finding the nearest server on the circle. Now, if you add a new server, only a portion of the data will need to be redistributed to accommodate it, rather than shifting all the data around. Similarly, if a server is removed, only the data that was assigned to it needs to be reassigned, keeping the system running smoothly with minimal reorganization.
To make things even more efficient, many implementations use virtual nodes. Instead of each server being assigned a single spot on the circle, each server can have multiple virtual spots. This helps in balancing the data more evenly and avoiding scenarios where some servers end up overloaded while others are underutilized.

Benefits of Consistent Hashing
One of the biggest advantages of consistent hashing is its scalability. As your system grows and you add more servers, consistent hashing ensures that data is redistributed with minimal impact. This means you can expand your system without experiencing major disruptions or slowdowns.
Another benefit is improved fault tolerance. In a traditional setup, removing a server could require redistributing a large chunk of data, which can be disruptive. With consistent hashing, only a small portion of data needs to be reassigned, reducing the impact of server failures and keeping your system resilient.
Consistent hashing also helps in maintaining a balanced load across servers. By distributing data more evenly, it prevents any single server from becoming a bottleneck, which helps in maintaining system performance and user satisfaction.
How to Implement Consistent Hashing in Your System
Implementing consistent hashing starts with choosing a suitable hash function. This function is crucial as it determines how data and servers are mapped onto the hash circle. The choice of hash function can affect the evenness of data distribution and overall system performance.
Next, consider implementing virtual nodes. By assigning multiple virtual nodes to each physical server, you can achieve a more balanced distribution of data and reduce the likelihood of hotspots. This step ensures that even as the number of servers changes, data remains evenly distributed.
Finally, regular monitoring and optimization are key. Keep an eye on how well the consistent hashing mechanism is performing and make adjustments as needed. This might involve tuning hash functions, adjusting virtual nodes, or tweaking other parameters to adapt to changing workloads and server capacities.
Common Consistent Hashing Challenges and Solutions
One challenge with consistent hashing is dealing with data skew. Sometimes, despite the best efforts, data may still end up unevenly distributed across servers. To address this, you might need to periodically rebalance data or use more sophisticated hashing techniques to ensure an even distribution.
Another issue is the overhead of rebalancing data when nodes change. While consistent hashing minimizes disruption, some data movement is inevitable. Using efficient algorithms and optimizing your hash function can help reduce this overhead and maintain system performance.
Managing the complexity of consistent hashing can also be a challenge. It requires careful planning and implementation. Ensuring that you have the right tools and expertise in place will help manage this complexity and reap the benefits of consistent hashing.
Case Studies: Successful Consistent Hashing Implementations
Consider a large-scale e-commerce site that uses consistent hashing to handle its vast and ever-growing product catalog. By implementing consistent hashing, the site efficiently distributes its product data across a dynamic cluster of servers, allowing for seamless scaling and uninterrupted service even during peak shopping seasons.
Another example is a global social media platform that uses consistent hashing to manage user data. The platform can quickly add new servers to handle increased user activity, ensuring that user data is distributed and accessed efficiently without causing service disruptions.
Future Trends in Consistent Hashing
As technology evolves, so will consistent hashing techniques. Innovations in hashing algorithms may offer even more precise and efficient data distribution methods. Future trends might include integrating machine learning to dynamically adjust hashing strategies based on real-time data and traffic patterns.
Advancements in distributed system design will continue to enhance the capabilities of consistent hashing, making it an even more powerful tool for managing scalable and resilient systems.
Consistent hashing is a vital technique for managing data distribution in distributed systems. By efficiently handling server changes and maintaining balanced load distribution, it helps ensure that your system remains scalable, resilient, and performant. Explore consistent hashing to improve your system’s efficiency and share your experiences or ask questions about its implementation in the comments!



